Metodología y plan de trabajo¶
Introducción¶
Como hemos visto en el estudio del estado del arte de los principales sistemas de almacenamiento Big Data, nos encontramos ante un ecosistema heterogéneo en cuanto a tipos de almacenamiento, procesamiento, despliegue, etc.
Aún siendo un ecosistema tan heterógeneo, es importante definir una metodología clara y sistemática en cuanto al desarrollo de conectores Big Data para CARTO. Esto es así, porque es de esperar que este campo siga evolucionando, surgiendo nuevas tecnologías y paradigmas a los que se deba dar soporte.
Así pues, en la definición de esta metodología sistemática, debemos encontrar un nexo de unión entre todos estos sistemas y CARTO.
¿Cómo conectar con CARTO?¶
De acuerdo a la arquitectura de CARTO, la integración con sistemas de terceros se puede realizar a dos niveles:
- Utilizando sus APIs, algunas de las cuales exponen interfaces para acceder directamente a todas las capacidades de PostgreSQL a través de SQL estándar.
- Utilizando las capacidades de conectividad de PostgreSQL, tales como Foreign Data Wrappers [1] (FDWs).
Una breve introducción a Foreign Data Wrappers (FDWs)¶
Antes de decidir qué aproximación vamos a utilizar para resolver el problema de conectar CARTO son sistemas de almacenamiento Big Data y ya que hemos mencionado FDWs como un solución válida para este problema, hagamos una pequeña introducción.
Los Foreign Data Wrappers son una funcionalidad del core de PostgreSQL que permite a desarrolladores exponer fuentes de datos externas como si fueran tablas dentro de PostgreSQL.
Para fuentes de datos que exponen tablas y un lenguaje de consulta SQL, FDWs actúa como un espejo de estos sistemas (Oracle, MySQL, etc.), para otros tipos de fuentes externas (APIs de redes sociales, CSVs, etc.) el FDW tiene que hacer esa conversión del modelo de datos y API de la fuente de datos de origen a tuplas de PostgreSQL.
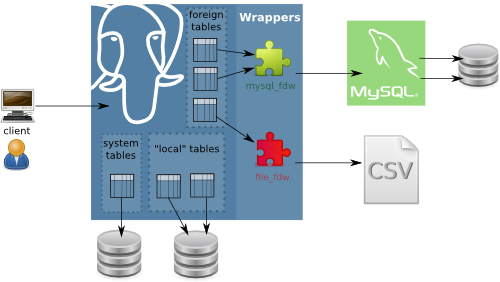
En cualquier caso, un FDW hace que PostgreSQL actúe como una especie de proxy entre la aplicación cliente que está ejecutando SQLs contra PostgreSQL y la fuente de datos externa, que recibe estas peticiones y contesta en consecuencia. A la vista del cliente, está trabajando directamente contra PostgreSQL.
APIs vs FDWs¶
Analizando las virtudes y defectos de ambas aproximaciones nos encontramos con lo siguiente:
A favor de la utilización de APIs como mecanismo de integración entre CARTO y otros sistemas está la flexibilidad. Estas APIs REST, se pueden utilizar en cualquier flujo de integración. Por otra parte, como inconveniente, nos encontramos con que se requieren desarrollos concretos para cada tipo de integración.
La utilización de las capacidades nativas de PostgreSQL para conectarse con sistemas de terceros presenta a su vez ventajas e inconvenientes. Entre las ventajas, cabe destacar, que el framework de Foreign Data Wrappers, consiste en un marco bien definido y ampliamente utilizado en la industria, que además, en gran parte de sus implementaciones se basa en la utilización de drivers ODBC [2], un estándar conocido y muy extendido en los sistemas de bases de datos relacionales.
El principal defecto de esta aproximación, consiste en la necesidad de realizar una conexión directa entre sistemas de bases de datos, en este caso, desde PostgreSQL a otros (tales como Hive, Impala, MongoDB, etc.). En algún caso, esto puede comprometer la seguridad de los sistemas de bases de datos.
Aún así, CARTO puede ser instalado on-premises, con lo que las organizaciones celosas de abrir una conexión fuera de su infraestrucura, podrían aprovecharse de este modo de integración.
Por último, y de nuevo haciendo referencia al estudio del estado del arte, hemos encontrado en todos los sistemas de almacenamiento Big Data dos puntos a favor de esta segunda aproximación:
- Todos los sistemas cuentan con driver ODBC
- Todos los sistemas cuentan con interfaz SQL o implementación de Foreign Data Wrapper específica para PostgreSQL
Con esto, podemos concluir que la utilización de Foreign Data Wrappers para conectar con sistemas de terceros, y en concreto, sistemas de almacenamiento Big Data, desde PostgreSQL es una solución factible y que además es susceptible de sistematizar.
Metodología¶
Con esta premisa, vamos a definir, una metodología, que se pueda probar y repetir, para conectar CARTO con Hive, Impala, Redshift, BigQuery, MongoDB y en definitiva, cualquier sistema de almacenamiento.
Esta metodología consta de 5 fases, que se desarrollarán para cada sistema en la siguiente sección Desarrollo del trabajo y resultados obtenidos y que se enumeran a continuación:
- Despliegue de un entorno de prueba del sistema de almacenamiento Big Data
- Búsqueda, instalación y prueba de un driver ODBC compatible
- Búsqueda, instalación y prueba de un Foreign Data Wrapper (opcionalmente se puede utilizar la implementación base de PostgreSQL o implementar una propia)
- Desarrollo de un conector para CARTO
- Ingestión de datos hacia CARTO
Plan de trabajo¶
El trabajo final de máster consta de 3 grandes bloques en su desarrollo.
- Despliegue de distintos sistemas de almacenamiento Big Data en la nube de Amazon.
- Desarrollo de conectores para CARTO.
- Ingestión de datos de prueba y creación de un dashboard de visualización de datos geoespaciales con CARTO provenientes de uno o más de los sistemas implementados.
El plan de trabajo detallado consiste en las siguientes tareas:
Despliegue de sistemas de almacenamiento Big Data en la nube de Amazon¶
Esta tarea consiste en explorar las diferentes alternativas para desplegar sistemas de almacenamiento Big Data en la nube.
El objetivo no es contar con despliegues robustos, resistentes a fallos o configurados en cluster, sino contar con diferentes entornos para realizar la ingestión de datos de prueba y conexión necesaria durante el desarrollo y demostración de los conectores para CARTO.
Para el desarrollo de este bloque se realizan las siguientes tareas:
- Aprovisionamiento de máquinas virtuales utilizando el servicio EC2 de Amazon, sobre una AMI de Ubuntu 14.04 y utilizando los servicios adicionales para configuración de firewall, control de acceso, disco, etc.
- Despliegue con Docker de Cloudera Quickstart para contar con instancias de Hive e Impala.
- Despliegue de una instancia de Amazon Redshift.
- Despliegue con Docker de una instancia de MongoDB.
- Configuración de una cuenta y credenciales para acceso a Google BigQuery.
Desarrollo de conectores para CARTO¶
Este bloque consiste en la implementación y prueba de los diferentes módulos que permitan conectar CARTO con los sistemas de almacenamiento mencionados previamente a través de su API de importación.
En este caso, el objetivo consiste en contar con conectores integrados en el código base de CARTO, de manera que sean incluidos en su versión on premise.
Para el desarrollo de deste bloque se realizan las siguientes tareas:
- Configuración de un entorno de desarrollo de CARTO utilizando Github, BASH y Vagrant.
- Desarrollo en Ruby del código necesario para los conectores.
- Configuración de las llamadas necesarias a la API REST de importación de CARTO.
- Documentación y scripts de configuración de los drivers necesarios para conectar con cada sistema de almacenamiento.
- Despliegue de CARTO en un servidor de staging en Amazon.
Ingestión de datos de prueba y creación de dashboard con CARTO¶
Una vez desplegados diferentes sistemas de almacenamiento Big Data en la nube, desarrollados los conectores y desplegada una instancia de CARTO, el último bloque consiste en realizar una pequeña demostración sobre un dashboard que consuma datos obtenidos de uno o más de estos sistemas desplegados.
Para el desarrollo de deste bloque se realizan las siguientes tareas:
- Ingestión de datos en los distintos sistemas de almacenamiento provistos.
- Ejecución de las llamadas necesarias mediante la API de importación de CARTO para conectar con uno o más sistemas de almacenamiento.
- Creación de un dashboard de análisis y visualización de datos geoespaciales con CARTO provenientes de uno o más de los sistemas implementados.
Metodología de trabajo¶
Para llevar a cabo el plan de trabajo se va a seguir una metodología de desarrollo iterativo incremental. Se trata de una metodología de desarrollo de software ágil que consiste en la ejecución de las distintas fases del proyecto en ciclos cortos de pocos días que se repiten en el tiempo, de manera que se va incrementando el valor de la solución final.
Esta metodología nos va a permitir validar en una frase temprana la solución propuesta, realizando una iteración que permita validar la integración de Hive e Impala con CARTO.
Una vez validado uno de estos sistemas de almacenamiento, se continúan realizando iteraciones cortas en las que se va dando soporte al resto de sistemas de almacenamiento propuestos, hasta contar con la solución completa.
En última instancia, se trabaja en la ingestión de datos y creación del dashboard a modo de demostración.
| [1] | https://carto.com/blog/postgres-fdw/ - mayo 2019 |
| [2] | https://docs.microsoft.com/en-us/sql/odbc/reference/what-is-odbc?view=sql-server-2017 - mayo 2019 |